Differences between Connected and Unconnected Lookup?
The
differences are illustrated in the below table
Connected Lookup
|
Unconnected Lookup
|
Connected
lookup participates in dataflow and receives input directly from the pipeline
|
Unconnected
lookup receives input values from the result of a LKP: expression in another
transformation
|
Connected
lookup can use both dynamic and static cache
|
Unconnected
Lookup cache can NOT be dynamic
|
Connected
lookup can return more than one column value ( output port )
|
Unconnected
Lookup can return only one column value i.e. output port
|
Connected
lookup caches all lookup columns
|
Unconnected
lookup caches only the lookup output ports in the lookup conditions and the
return port
|
Supports
user-defined default values (i.e. value to return when lookup conditions are
not satisfied)
|
Does
not support user defined default values
|
What is
meant by active and passive transformation?
An active transformation is the one that performs
any of the following actions:
1) Change the number of rows between transformation
input and output. Example: Filter transformation.
2) Change the transaction boundary by defining
commit or rollback points. Example transaction control transformation.
3) Change the row type, example Update strategy is
active because it flags the rows for insert, delete, update or reject.
On
the other hand a passive transformation is the one which does not change the
number of rows that pass through it. Example: Expression transformation.
What is the difference between Router and Filter?
Following
differences can be noted,
Router
|
Filter
|
Router
transformation divides the incoming records into multiple groups based on
some condition. Such groups can be mutually inclusive (Different groups may
contain same record)
|
Filter
transformation restricts or blocks the incoming record set based on one given
condition.
|
Router
transformation itself does not block any record. If a certain record does not
match any of the routing conditions, the record is routed to default group
|
Filter
transformation does not have a default group. If one record does not match
filter condition, the record is blocked
|
Router
acts like CASE... WHEN statement
in SQL (Or Switch ()... Case
statement in C)
|
Filter
acts like WHERE condition is SQL.
|
What can we do to improve the performance of Informatica
Aggregator Transformation?
Aggregator
performance improves dramatically if records are sorted before passing to the
aggregator and "sorted input" option under aggregator properties is
checked. The record set should be sorted on those columns that are used in
Group By operation.
It
is often a good idea to sort the record set in database level e.g. inside a
source qualifier transformation, unless there is a chance that already sorted
records from source qualifier can again become unsorted before reaching
aggregator
What are the different lookup cache(s)?
Informatica
Lookups can be cached or un-cached (No cache). And Cached lookup can be either
static or dynamic. A static cache is one which does not modify
the cache once it is built and it remains same during the session run. On the
other hand, a dynamic cache is
refreshed during the session run by inserting or updating the records in cache
based on the incoming source data. By default, Informatica cache is static
cache.
A
lookup cache can also be divided as persistent or non-persistent based on
whether Informatica retains the cache even after the completion of session run
or deletes it
How can we update a record in target table without using Update
strategy?
A
target table can be updated without using 'Update Strategy'. For this, we need
to define the key in the target table in Informatica level and then we need to
connect the key and the field we want to update in the mapping Target. In the
session level, we should set the target property as "Update as
Update" and check the "Update" check-box.
Let's
assume we have a target table "Customer" with fields as
"Customer ID", "Customer Name" and "Customer
Address". Suppose we want to update "Customer Address" without
an Update Strategy. Then we have to define "Customer ID" as primary
key in Informatica level and we will have to connect Customer ID and Customer
Address fields in the mapping. If the session properties are set correctly as
described above, then the mapping will only update the customer address field
for all matching customer IDs.
Under what condition selecting Sorted Input in aggregator may
fail the session?
§ If
the input data is not sorted correctly, the session will fail.
§ Also
if the input data is properly sorted, the session may fail if the sort order by
ports and the group by ports of the aggregator are not in the same order.
Why is Sorter an Active Transformation?
This
is because we can select the "distinct" option in the sorter
property.When
the Sorter transformation is configured to treat output row as distinct, it
assigns all ports as part of the sort key. The Integration Service discards
duplicate rows compared during the sort operation. The number of Input Rows
will vary as compared with the Output rows and hence it is an Active
transformation.
Is lookup an active or passive transformation?
From
Informatica 9x, Lookup transformation can be configured as as
"Active" transformation.
However,
in the older versions of Informatica, lookup is a passive transformation
What is the difference between Static and Dynamic Lookup Cache?
We
can configure a Lookup transformation to cache the underlying lookup table. In
case of static or read-only lookup cache the Integration Service caches the
lookup table at the beginning of the session and does not update the lookup
cache while it processes the Lookup transformation.
In
case of dynamic lookup cache the Integration Service dynamically inserts or
updates data in the lookup cache and passes the data to the target. The dynamic
cache is synchronized with the target.
What is
the difference between STOP and ABORT options in Workflow Monitor?
When
we issue the STOP command on the executing session task, the Integration
Service stops reading data from source. It continues processing, writing and
committing the data to targets. If the Integration Service cannot finish
processing and committing data, we can issue the abort command.
In
contrast ABORT command has a timeout period of 60 seconds. If the Integration
Service cannot finish processing and committing data within the timeout period,
it kills the DTM process and terminates the session.
What are the new features of Informatica 9.x in developer level?
From
a developer's perspective, some of the new features in Informatica 9.x are as
follows:
§ Now
Lookup can be configured as an active transformation - it can return multiple
rows on successful match
§ Now
you can write SQL override on un-cached lookup also. Previously you could do it
only on cached lookup
§ You
can control the size of your session log. In a real-time environment you can
control the session log file size or time
§ Database
deadlock resilience feature - this will ensure that your session does not
immediately fail if it encounters any database deadlock, it will now retry the
operation again. You can configure number of retry attempts.
How to delete duplicate row using Informatica
Duplicate rows are present in relational database
Suppose
we have Duplicate records in Source System and we want to load only the unique
records in the Target System eliminating the duplicate rows. What will be the
approach?
Assuming
that the source system is a Relational Database, to eliminate
duplicate records, we can check the distinct option of the Source
Qualifier of the source table and load the target accordingly.

{kind=link}
Deleting duplicate records from flat-file?
To
know the answer of the above question (and many more similar high frequency
Informatica questions) please continue
Deleting duplicate rows / selecting
distinct rows for FLAT FILE sources
In the previous page we saw how to choose distinct records from
Relational sources. Next we asked the question, how may we select the distinct
records for Flat File sources?
Here since the source system is a Flat File you will not be able to select the
distinct option in the source qualifier as it will be disabled due to flat file
source table. Hence the next approach may be we use a Sorter Transformation and check the distinct option. When we select the distinct
option all the columns will the selected as keys, in ascending order by
default.

{kind=link}
Deleting Duplicate Record Using
Informatica Aggregator
Other ways to handle duplicate records in source batch run is to
use an Aggregator
Transformation and using the Group by checkbox on the ports having duplicate
occurring data. Here you can have the flexibility to select the last or the first of the duplicate column value records.
There is yet another option to ensure duplicate records are not
inserted in the target. That is through Dynamic lookup cache. Using Dynamic
Lookup Cache of the target table and associating the input ports with the
lookup port and checking the Insert Else Update option will help to eliminate
the duplicate records in source and hence loading unique records in the target.
Loading Multiple Target Tables Based
on Conditions
Q 03. Suppose we have some serial numbers in a flat file source.
We want to load the serial numbers in two target files one containing the EVEN
serial numbers and the other file having the ODD ones.
Answer:
After the Source Qualifier place a Router Transformation. Create
two Groups namely EVEN and ODD, with filter
conditions as:
MOD(SERIAL_NO,2)=0 and MOD(SERIAL_NO,2)=1
... respectively. Then output the two groups into two flat file
targets.

{kind=link}
Normalizer Related Questions
Q 04. Suppose in our Source Table we have data as given below:
Student Name
|
Maths
|
Life Science
|
Physical Science
|
Sam
|
100
|
70
|
80
|
John
|
75
|
100
|
85
|
Tom
|
80
|
100
|
85
|
We want to load our Target Table as:
Student Name
|
Subject Name
|
Marks
|
Sam
|
Maths
|
100
|
Sam
|
Life Science
|
70
|
Sam
|
Physical Science
|
80
|
John
|
Maths
|
75
|
John
|
Life Science
|
100
|
John
|
Physical Science
|
85
|
Tom
|
Maths
|
80
|
Tom
|
Life Science
|
100
|
Tom
|
Physical Science
|
85
|
Describe your approach.
Answer
Here to convert the Rows to Columns we have to use the Normalizer Transformation followed by an Expression
Transformation to decode the column taken into consideration.
Q 05. Name the transformations which converts one to many rows
i.e increases the i/p:o/p row count. Also what is the name of its reverse transformation?
Answer: Normalizer as
well as Router Transformations are the Active
transformation which can increase the number of input rows to output rows.
Aggregator Transformation performs the reverse action of Normalizer
transformation.
Q 06. Suppose we have a
source table and we want to load three target tables based on source rows such
that first row moves to first target table, secord row in second target table,
third row in third target table, fourth row again in first target table so on and
so forth. Describe your approach.
Answer: We can clearly understand that we need a Router transformation to route or filter source data to the
three target tables. Now the question is what will be the filter conditions.
First of all we need an Expression
Transformation where we have
all the source table columns and along with that we have another i/o port say
seq_num, which is gets sequence numbers for each source row from the port NextVal of a Sequence
Generator start value 0 and increment by 1. Now the filter condition for
the three router groups will be:
§ MOD(SEQ_NUM,3)=1 connected to 1st target table
§ MOD(SEQ_NUM,3)=2 connected to 2nd target table
§ MOD(SEQ_NUM,3)=0 connected to 3rd target table

{kind=link}
Loading Multiple Flat Files using one mapping
Q 07. Suppose we have ten
source flat files of same structure. How can we load all the files in target
database in a single batch run using a single mapping?
Answer: After we create a mapping to load data in target
database from flat files, next we move on to the session property of the Source
Qualifier. To load a set of source files we need to create a file say final.txt
containing the source flat file names, ten files in our case and set the Source file type option as Indirect. Next point this flat
file final.txt fully qualified through Source file directory and Source
filename.

{kind=link}
Aggregator Transformation Related
Questions
Q 08. How can we implement
Aggregation operation without using an Aggregator Transformation in
Informatica?
Answer
We will use the very basic concept of the Expression Transformation that at a time we can access the
previous row data as well as the currently processed data in an expression
transformation. What we need is simple Sorter, Expression and Filter
transformation to achieve aggregation at Informatica level.
Q 09. Suppose in our Source
Table we have data as given below:
Student Name
|
Subject Name
|
Marks
|
Sam
|
Maths
|
100
|
Tom
|
Maths
|
80
|
Sam
|
Physical Science
|
80
|
John
|
Maths
|
75
|
Sam
|
Life Science
|
70
|
John
|
Life Science
|
100
|
John
|
Physical Science
|
85
|
Tom
|
Life Science
|
100
|
Tom
|
Physical Science
|
85
|
We want to load our Target Table as:
Student Name
|
Maths
|
Life Science
|
Physical Science
|
Sam
|
100
|
70
|
80
|
John
|
75
|
100
|
85
|
Tom
|
80
|
100
|
85
|
Describe your approach.
Answer
Here our scenario is to convert many rows to one rows, and the
transformation which will help us to achieve this is Aggregator.
Our Mapping will look like this:

We will sort the source data based on STUDENT_NAME ascending
followed by SUBJECT ascending.

{kind=link}
Now based on STUDENT_NAME in GROUP
BY clause the following
output subject columns are populated as
§ MATHS: MAX(MARKS, SUBJECT=Maths)
§ LIFE_SC: MAX(MARKS, SUBJECT=Life Science)
§ PHY_SC: MAX(MARKS, SUBJECT=Physical Science)

{kind=link}
Revisiting Source Qualifier
Transformation
Q10. What is a Source
Qualifier? What are the tasks we can perform using a SQ and why it is an ACTIVE
transformation?
Ans. A Source Qualifier is an Active and Connected Informatica
transformation that reads the rows from a relational database or flat file
source.
§ We can configure the SQ to join [Both INNER as well as OUTER JOIN] data originating from
the same source database.
§ We can use a source filter to reduce the number of rows the
Integration Service queries.
§ We can specify a number for sorted
ports and the Integration
Service adds an ORDER BY clause to the default SQL query.
§ We can choose Select
Distinct option for relational databases and the Integration Service adds a
SELECT DISTINCT clause to the default SQL query.
§ Also we can write Custom/Used
Defined SQL query which will
override the default query in the SQ by changing the default settings of the
transformation properties.
§ Also we have the option to write Pre as well as Post SQL statements to be executed before and
after the SQ query in the source database.
Since the transformation provides us with the property Select Distinct, when the Integration
Service adds a SELECT DISTINCT clause to the default SQL query, which in turn
affects the number of rows returned by the Database to the Integration Service
and hence it is an Active transformation.
Q11. What happens to a
mapping if we alter the datatypes between Source and its corresponding Source
Qualifier?
Ans. The
Source Qualifier transformation displays the transformation datatypes. The
transformation datatypes determine how the source database binds data when the
Integration Service reads it.
Now if we alter the datatypes in the Source Qualifier
transformation or the datatypes
in the source definition and Source Qualifier transformation do not match, the Designer marks the mapping as invalid when we save it.
Q12. Suppose we have used
the Select Distinct and the Number of Sorted Ports property in the SQ and then
we add Custom SQL Query. Explain what will happen.
Ans. Whenever
we add Custom SQL or SQL override query it overrides the User-Defined Join, Source Filter,
Number of Sorted Ports, and Select Distinct settings in the Source Qualifier
transformation. Hence only the user defined SQL Query will be fired in the
database and all the other
options will be ignored.
Q13. Describe the
situations where we will use the Source Filter, Select Distinct and Number of
Sorted Ports properties of Source Qualifier transformation.
Ans. Source
Filter option
is used basically to reduce the number of rows the Integration Service queries
so as to improve performance.
Select Distinct option
is used when we want the Integration Service to select unique values from a
source, filtering out unnecessary data earlier in the data flow, which might
improve performance.
Number Of Sorted Ports option is used when we want the source data to be in a sorted
fashion so as to use the same in some following transformations like Aggregator
or Joiner, those when configured for sorted input will improve the performance.
Q14. What will happen if
the SELECT list COLUMNS in the Custom override SQL Query and the OUTPUT PORTS
order in SQ transformation do not match?
Ans. Mismatch
or changing the order of the list of selected columns to that of the connected
transformation output ports may result is session
failure.
Q15. What happens if in
the Source Filter property of SQ transformation we include keyword WHERE say,
WHERE CUSTOMERS.CUSTOMER_ID > 1000.
Ans. We
use source filter to reduce the number of source records. If we include the
string WHERE in the source filter, the Integration
Service fails the session.
Q16. Describe the
scenarios where we go for Joiner transformation instead of Source Qualifier
transformation.
Ans. While
joining Source Data of heterogeneous
sources as well as to join flat files we will use the Joiner transformation.
Use the Joiner transformation when we need to join the following types of
sources:
§ Join data from different Relational Databases.
§ Join data from different Flat Files.
§ Join relational sources and flat files.
Q17. What is the maximum
number we can use in Number of Sorted Ports for Sybase source system?
Ans. Sybase
supports a maximum of 16 columns in an ORDER BY clause. So if
the source is Sybase, do not sort more than 16 columns.
Q18. Suppose we have two
Source Qualifier transformations SQ1 and SQ2 connected to Target tables TGT1
and TGT2 respectively. How do you ensure TGT2 is loaded after TGT1?
Ans. If we
have multiple Source Qualifier transformations connected to multiple targets,
we can designate the order in which the Integration Service loads data into the
targets.
In the Mapping Designer, We need to configure the Target Load Plan based on the Source Qualifier
transformations in a mapping to specify the required loading order.

{kind=link}
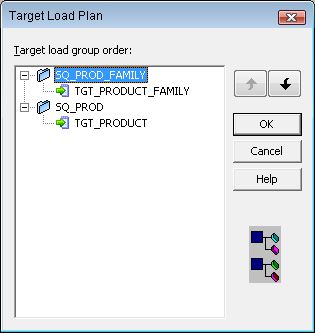
Que: we have a Source Qualifier transformation that populates
two target tables. How do you ensure TGT2 is loaded after TGT1?
Ans. In
the Workflow Manager, we can Configure Constraint
based load ordering for a
session. The Integration Service orders the target load on a row-by-row basis.
For every row generated by an active source, the Integration Service loads the
corresponding transformed row first to the primary key table, then to the
foreign key table.
Hence if we have one Source Qualifier transformation that
provides data for multiple target tables having primary and foreign key
relationships, we will go for Constraint based load ordering.

{kind=link}
Filter Transformation
Q19. What
is a Filter Transformation and why it is an Active one?
Ans. A Filter transformation is an Active and Connected transformation that can filter rows in
a mapping.
Only the rows that meet the Filter
Condition pass through the
Filter transformation to the next transformation in the pipeline. TRUE and
FALSE are the implicit return values from any filter condition we set. If the
filter condition evaluates to NULL, the row is assumed to be FALSE.
The numeric equivalent of FALSE is zero (0) and any non-zero
value is the equivalent of TRUE.
As an ACTIVE transformation, the Filter
transformation may change the number of rows passed through it. A filter
condition returns TRUE or FALSE for each row that passes through the
transformation, depending on whether a row meets the specified condition. Only
rows that return TRUE pass through this transformation. Discarded rows do not
appear in the session log or reject files.
Q20. What
is the difference between Source Qualifier transformations Source Filter to filter
transformation?
Ans.
SQ Source Filter
|
Filter Transformation
|
Source Qualifier transformation filters rows when read from a
source.
|
Filter transformation filters rows from within a mapping
|
Source Qualifier transformation can only filter rows from
Relational Sources.
|
Filter transformation filters rows coming from any type of
source system in the mapping level.
|
Source Qualifier limits the row set extracted from a source.
|
Filter transformation limits the row set sent to a target.
|
Source Qualifier reduces the number of rows used throughout
the mapping and hence it provides better performance.
|
To maximize session performance, include the Filter
transformation as close to the sources in the mapping as possible to filter
out unwanted data early in the flow of data from sources to targets.
|
The filter condition in the Source Qualifier transformation
only uses standard SQL as it runs in the database.
|
Filter Transformation can define a condition using any statement
or transformation function that returns either a TRUE or FALSE value.
|
Revisiting Joiner Transformation
Q21. What
is a Joiner Transformation and why it is an Active one?
Ans. A Joiner is an Active and connected transformation used to join source data
from the same source system or from two related heterogeneous sources residing
in different locations or file systems.
The Joiner transformation joins sources with at least one
matching column. The Joiner transformation uses a condition that matches one or
more pairs of columns between the two sources.
The two input pipelines include a master pipeline and a detail
pipeline or a master and a detail branch. The master pipeline ends at the
Joiner transformation, while the detail pipeline continues to the target.
In the Joiner transformation, we must configure the
transformation properties namely Join Condition, Join Type and Sorted Input
option to improve Integration Service performance.
The join condition contains ports from both input sources that
must match for the Integration Service to join two rows. Depending on the type
of join selected, the Integration Service either adds the row to the result set or
discards the row.
The Joiner transformation produces result sets based on the join
type, condition, and input data sources. Hence it is an Active transformation.
Q22. State
the limitations where we cannot use Joiner in the mapping pipeline.
Ans. The
Joiner transformation accepts input from most transformations. However,
following are the limitations:
§ Joiner transformation cannot be used when either of the input
pipeline contains an Update
Strategy transformation.
§ Joiner transformation cannot be used if we connect a Sequence Generator transformation directly before the
Joiner transformation.
Q23. Out
of the two input pipelines of a joiner, which one will you set as the master
pipeline?
Ans. During
a session run, the Integration Service compares each row of the master source against the detail source. The master
and detail sources need to be configured for optimal
performance.
To improve performance for an Unsorted
Joiner transformation, use
the source with fewer rows as the master source. The fewer unique
rows in the master, the fewer iterations of the join comparison occur, which
speeds the join process.
When the Integration Service processes an unsorted Joiner
transformation, it reads all master rows before it reads the detail rows. The
Integration Service blocks the detail source while it caches rows from the master source.
Once the Integration Service reads and caches all master rows, it unblocks the
detail source and reads the detail rows.
To improve performance for a Sorted
Joiner transformation, use
the source with fewer
duplicate key values as the
master source.
When the Integration Service processes a sorted Joiner
transformation, it blocks data based on the mapping configuration and it stores fewer rows in the cache, increasing performance.
Blocking logic is possible if master and detail input to the
Joiner transformation originate from different
sources. Otherwise, it does not use blocking logic. Instead, it stores more rows in the cache.
Q24. What
are the different types of Joins available in Joiner Transformation?
Ans. In
SQL, a join is a relational operator that combines data from multiple tables into
a single result set. The Joiner transformation is similar to an SQL join except
that data can originate from different types of sources.
The Joiner transformation supports the following types of joins:
§ Normal
§ Master Outer
§ Detail Outer
§ Full Outer

{kind=link}
Note: A normal or master outer join performs
faster than a full outer or
detail outer join.
Q25. Define
the various Join Types of Joiner Transformation.
Ans.
§ In a normal join, the Integration Service discards all rows
of data from the master and detail source that do not match, based on the join
condition.
§ A master outer
join keeps all rows of data
from the detail source and the matching rows from the master source. It
discards the unmatched rows from the master source.
§ A detail outer join keeps all rows of data from the
master source and the matching rows from the detail source. It discards the
unmatched rows from the detail source.
§ A full outer join keeps all rows of data from both
the master and detail sources.
Q26. Describe
the impact of number of join conditions and join order in a Joiner
Transformation.
Ans. We
can define one or more
conditions based on equality between the specified master and
detail sources. Both ports in a condition must have the same datatype.
If we need to use two ports in the join condition with
non-matching datatypes we must convert the datatypes so that they match. The
Designer validates datatypes in a join condition.
Additional ports in
the join condition increases
the time necessary to join
two sources.
The order of the ports in the join condition can impact the
performance of the Joiner transformation. If we use multiple ports in the join
condition, the Integration Service compares the ports in the order we
specified.
NOTE: Only
equality operator is available in joiner join condition.
Q27. How
does Joiner transformation treat NULL value matching?
Ans. The
Joiner transformation does not
match null values.
For example, if both EMP_ID1 and EMP_ID2 contain a row with a
null value, the Integration Service does not consider them a match and does not
join the two rows.
To join rows with null values, replace null input with default values in the Ports tab of the joiner, and
then join on the default values.
Note: If a
result set includes fields that do not contain data in either of the sources,
the Joiner transformation populates the empty fields with null values. If we
know that a field will return a NULL and we do not want to insert NULLs in the
target, set a default value on the Ports tab for the corresponding port.
Q28. Suppose
we configure Sorter transformations in the master and detail pipelines with the
following sorted ports in order: ITEM_NO, ITEM_NAME, and PRICE.
When we configure the join condition, what are the guidelines
we need to follow to maintain the sort order?
Ans. If we
have sorted both the master and detail pipelines in order of the ports say
ITEM_NO, ITEM_NAME and PRICE we must ensure that:
§ Use ITEM_NO in the First Join Condition.
§ If we add a Second Join Condition, we must use ITEM_NAME.
§ If we want to use PRICE as a Join Condition apart from ITEM_NO,
we must also use ITEM_NAME in the Second Join Condition.
§ If we skip ITEM_NAME and join on ITEM_NO and PRICE, we will lose the input sort order and the Integration Service fails the session.
Q29. What
are the transformations that cannot be placed between the sort origin and the
Joiner transformation so that we do not lose the input sort order?
Ans. The
best option is to place the Joiner transformation directly after the sort
origin to maintain sorted data. However do not place any of the following
transformations between the sort origin and the Joiner transformation:
§ Custom
§ Unsorted Aggregator
§ Normalizer
§ Rank
§ Union transformation
§ XML Parser transformation
§ XML Generator transformation
§ Mapplet [if it contains any one of the above mentioned
transformations]
Q30. Suppose
we have the EMP table as our source. In the target we want to view those
employees whose salary is greater than or equal to the average salary for their
departments. Describe your mapping approach.
Ans. Our
Mapping will look like this:

To start with the mapping we need the following transformations:
After the Source qualifier of the EMP table place a Sorter Transformation. Sort based on DEPTNO port.

{kind=link}
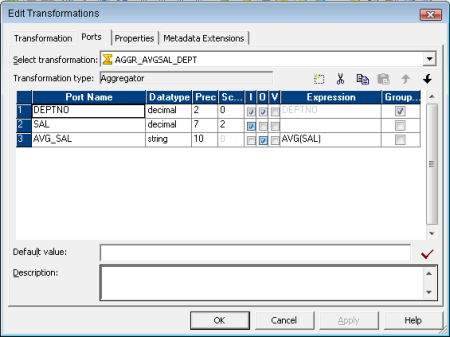
Next we place a Sorted
Aggregator Transformation. Here we will find out the AVERAGE SALARY for each (GROUP BY) DEPTNO.
When we perform this aggregation, we lose the data for
individual employees.
To maintain employee data, we must pass a branch of the pipeline
to the Aggregator Transformation and pass a branch with the same sorted source
data to the Joiner transformation to maintain the original data.
When we join both branches of the pipeline, we join the
aggregated data with the original data.

{kind=link}
{kind=link}
So next we need Sorted
Joiner Transformation to join
the sorted aggregated data with the original data, based on DEPTNO. Here
we will be taking the aggregated pipeline as the Master and original dataflow
as Detail Pipeline.


{kind=link}
{kind=link}
After that we need a Filter
Transformation to filter out
the employees having salary less than average salary for their department.
Filter Condition: SAL>=AVG_SAL

{kind=link}
Lastly we have the Target table instance.
Sequence Generator Transformation
Q31. What
is a Sequence Generator Transformation?
Ans. A Sequence Generator transformation is a Passive and Connected transformation that generates numeric
values. It is used to create unique primary key values, replace missing primary
keys, or cycle through a sequential range of numbers. This transformation by default contains ONLY Two OUTPUT ports namely CURRVAL and NEXTVAL.
We cannot edit or delete these ports neither we cannot add ports to this unique
transformation. We can create approximately two billion unique numeric values
with the widest range from 1 to 2147483647.
Q32. Define
the Properties available in Sequence Generator transformation in brief.
Ans.
Sequence Generator Properties
|
Description
|
Start Value
|
Start value of the generated sequence that we want the
Integration Service to use if we use the Cycle option. If we select Cycle,
the Integration Service cycles back to this value when it reaches the end
value. Default is 0.
|
Increment By
|
Difference between two consecutive values from the NEXTVAL
port.Default is 1.
|
End Value
|
Maximum value generated by SeqGen. After reaching this value
the session will fail if the sequence generator is not configured to
cycle.Default is 2147483647.
|
Current Value
|
Current value of the sequence. Enter the value we want the
Integration Service to use as the first value in the sequence. Default is 1.
|
Cycle
|
If selected, when the Integration Service reaches the
configured end value for the sequence, it wraps around and starts the cycle
again, beginning with the configured Start Value.
|
Number of Cached Values
|
Number of sequential values the Integration Service caches at
a time. Default value for a standard Sequence Generator is 0. Default value
for a reusable Sequence Generator is 1,000.
|
Reset
|
Restarts the sequence at the current value each time a session
runs.This option is disabled for reusable Sequence Generator transformations.
|
Q33. Suppose we have a source table populating two target tables. We connect the NEXTVAL port of the Sequence Generator to the surrogate keys of both the target tables.
Will the Surrogate keys in both the target tables be same? If
not how can we flow the same sequence values in both of them.
Ans. When
we connect the NEXTVAL output port of the Sequence Generator directly to the surrogate key columns
of the target tables, the Sequence
number will not be the same.
A block of sequence numbers is sent to one target tables
surrogate key column. The second targets receives a block of sequence numbers
from the Sequence Generator transformation only after the first target table
receives the block of sequence numbers.
Suppose we have 5 rows coming from the source, so the targets
will have the sequence values as TGT1 (1,2,3,4,5) and TGT2 (6,7,8,9,10). [Taken
into consideration Start Value 0, Current value 1 and Increment by 1.
Now suppose the requirement is like that we need to have the
same surrogate keys in both the targets.
Then the easiest way to handle the situation is to put an Expression Transformation in between the Sequence Generator and
the Target tables. The SeqGen will pass unique values to the expression
transformation, and then the rows are routed from the expression transformation
to the targets.

Q34. Suppose
we have 100 records coming from the source. Now for a target column population
we used a Sequence generator.
Suppose the Current Value is 0 and End Value of Sequence
generator is set to 80. What will happen?
Ans. End
Value is
the maximum value the Sequence Generator will generate. After it reaches the
End value the session fails with the following error message:
TT_11009 Sequence Generator Transformation: Overflow error.
Failing of session can be handled if the Sequence Generator is
configured to Cycle through the sequence, i.e. whenever
the Integration Service reaches the configured end value for the sequence, it
wraps around and starts the cycle again, beginning with the configured Start
Value.
Q35. What
are the changes we observe when we promote a non-reusable Sequence Generator to
a reusable one? And what happens if we set the Number of Cached Values to 0 for
a reusable transformation?
Ans. When
we convert a non-reusable sequence generator to reusable one we observe that
the Number of Cached Values
is set to 1000 by default; and the Reset property is disabled.
When we try to set the Number
of Cached Values property of
a Reusable Sequence Generator to 0 in the Transformation Developer we encounter
the following error message:
The number of cached values must be greater than zero for
reusable sequence transformation.
Revisiting Aggregator Transformation
Q36. What
is an Aggregator Transformation?
Ans. An
aggregator is an Active, Connected transformation which performs aggregate
calculations like AVG, COUNT, FIRST, LAST, MAX, MEDIAN, MIN, PERCENTILE, STDDEV, SUM and VARIANCE.
Q37. How
an Expression Transformation differs from Aggregator Transformation?
Ans. An
Expression Transformation performs calculation on a row-by-row basis. An Aggregator Transformation
performs calculations on
groups.
Q38. Does
an Informatica Transformation support only Aggregate expressions?
Ans. Apart
from aggregate expressions Informatica Aggregator also supports non-aggregate
expressions and conditional clauses.
Q39. How
does Aggregator Transformation handle NULL values?
Ans. By
default, the aggregator transformation treats null values as NULL in aggregate
functions. But we can specify to treat null values in aggregate functions as
NULL or zero.
Q40. What
is Incremental Aggregation?
Ans. We
can enable the session option, Incremental Aggregation for a session that
includes an Aggregator Transformation. When the Integration Service performs
incremental aggregation, it actually passes changed source data through the
mapping and uses the historical cache data to perform aggregate calculations
incrementally.
Q41. What
are the performance considerations when working with Aggregator Transformation?
Ans.
§ Filter the unnecessary data before aggregating it. Place a
Filter transformation in the mapping before the Aggregator transformation to
reduce unnecessary aggregation.
§ Improve performance by connecting only the necessary
input/output ports to subsequent transformations, thereby reducing the size of
the data cache.
§ Use Sorted input which reduces the amount of data cached and
improves session performance.
Q42. What
differs when we choose Sorted Input for Aggregator Transformation?
Ans. Integration
Service creates the index and data caches files in memory to process the
Aggregator transformation. If the Integration Service requires more space as
allocated for the index and data cache sizes in the transformation properties,
it stores overflow values in cache files i.e. paging to disk. One way to
increase session performance is to increase the index and data cache sizes in
the transformation properties. But when we check Sorted Input the Integration
Service uses memory to process an Aggregator transformation it does not use
cache files.
Q43. Under
what conditions selecting Sorted Input in aggregator will still not boost
session performance?
Ans.
§ Incremental Aggregation, session option is enabled.
§ The aggregate expression contains nested aggregate functions.
§ Source data is data driven.
Q44. Under
what condition selecting Sorted Input in aggregator may fail the session?
Ans.
§ If the input data is not sorted correctly, the session will
fail.
§ Also if the input data is properly sorted, the session may fail
if the sort order by ports and the group by ports of the aggregator are not in
the same order.
Q45. Suppose
we do not group by on any ports of the aggregator what will be the output.
Ans. If we
do not group values, the Integration Service will return only the last row for the input rows.
Q46. What
is the expected value if the column in an aggregator transform is neither a
group by nor an aggregate expression?
Ans. Integration
Service produces one row for each group based on the group by ports. The
columns which are neither part of the key nor aggregate expression will return
the corresponding value of last record of the group received. However, if we
specify particularly the FIRST function, the Integration Service then returns
the value of the specified first row of the group. So default is the LAST function.
Q47. Give
one example for each of Conditional Aggregation, Non-Aggregate expression and
Nested Aggregation.
Ans.
Use conditional clauses in the aggregate expression to reduce
the number of rows used in the aggregation. The conditional clause can be any
clause that evaluates to TRUE or FALSE.
SUM( SALARY, JOB = CLERK )
Use non-aggregate expressions in group by ports to modify or
replace groups.
IIF( PRODUCT = Brown Bread, Bread, PRODUCT )
The expression can also include one aggregate function within
another aggregate function, such as:
MAX( COUNT( PRODUCT ))
Revisiting Rank Transformation
Q48. What
is a Rank Transform?
Ans. Rank
is an Active Connected Informatica transformation used to select a set of top
or bottom values of data.
Q49. How
does a Rank Transform differ from Aggregator Transform functions MAX and MIN?
Ans. Like
the Aggregator transformation, the Rank transformation lets us group
information. The Rank Transform allows us to select a group of top or bottom values, not just one value as in case of Aggregator MAX, MIN
functions.
Q50. What
is a RANK port and RANKINDEX?
Ans. Rank
port is an input/output port use to specify the column for which we want to
rank the source values. By default Informatica creates an output port RANKINDEX
for each Rank transformation. It stores the ranking position for each row in a
group.
Q51. How
can you get ranks based on different groups?
Ans. Rank
transformation lets us group information. We can configure one of its
input/output ports as a group by port. For each unique value in the group port,
the transformation creates a group of rows falling within the rank definition
(top or bottom, and a particular number in each rank).
Q52. What
happens if two rank values match?
Ans. If
two rank values match, they receive the same value in the rank index and the
transformation skips the next value.
Q53. What
are the restrictions of Rank Transformation?
Ans.
§ We can connect ports from only one transformation to the Rank
transformation.
§ We can select the top or bottom rank.
§ We need to select the Number of records in each rank.
§ We can designate only one Rank port in a Rank transformation.
Q54. How
does a Rank Cache works?
Ans. During
a session, the Integration Service compares an input row with rows in the data
cache. If the input row out-ranks a cached row, the Integration Service
replaces the cached row with the input row. If we configure the Rank
transformation to rank based on different groups, the Integration Service ranks
incrementally for each group it finds. The Integration Service creates an index
cache to stores the group information and data cache for the row data.
Q55. How
does Rank transformation handle string values?
Ans. Rank
transformation can return the strings at the top or the bottom of a session
sort order. When the Integration Service runs in Unicode mode, it sorts
character data in the session using the selected sort order associated with the
Code Page of IS which may be French, German, etc. When the Integration Service
runs in ASCII mode, it ignores this setting and uses a binary sort order to
sort character data.
Revisiting Sorter Transformation
Q56. What
is a Sorter Transformation?
Ans. Sorter
Transformation is an Active, Connected Informatica transformation used to sort
data in ascending or descending order according to specified sort keys. The
Sorter transformation contains only input/output ports.
Q57. Why
is Sorter an Active Transformation?
Ans. When
the Sorter transformation is configured to treat output rows as distinct, it
assigns all ports as part of the sort key. The Integration Service discards
duplicate rows compared during the sort operation. The number of Input Rows
will vary as compared with the Output rows and hence it is an Active
transformation.
Q58. How
does Sorter handle Case Sensitive sorting?
Ans. The
Case Sensitive property determines whether the Integration Service considers
case when sorting data. When we enable the Case Sensitive property, the
Integration Service sorts uppercase characters higher than lowercase
characters.
Q59. How
does Sorter handle NULL values?
Ans. We
can configure the way the Sorter transformation treats null values. Enable the
property Null Treated Low if we want to treat null values as lower than any
other value when it performs the sort operation. Disable this option if we want
the Integration Service to treat null values as higher than any other value.
Q60. How
does a Sorter Cache works?
Ans. The
Integration Service passes all incoming data into the Sorter Cache before
Sorter transformation performs the sort operation.
The Integration Service uses the Sorter Cache Size property to
determine the maximum amount of memory it can allocate to perform the sort
operation. If it cannot allocate enough memory, the Integration Service fails
the session. For best performance, configure Sorter cache size with a value
less than or equal to the amount of available physical RAM on the Integration
Service machine.
If the amount of incoming data is greater than the amount of
Sorter cache size, the Integration Service temporarily stores data in the
Sorter transformation work directory. The Integration Service requires disk
space of at least twice the amount of incoming data when storing data in the
work directory.
Revisiting Union Transformation
Q61. What
is a Union Transformation?
Ans. The Union transformation is an Active, Connected non-blocking multiple input group transformation use to merge data from multiple pipelines or sources into one pipeline branch. Similar to the UNION ALL SQL statement, the Union transformation does not remove duplicate rows.
Ans. The Union transformation is an Active, Connected non-blocking multiple input group transformation use to merge data from multiple pipelines or sources into one pipeline branch. Similar to the UNION ALL SQL statement, the Union transformation does not remove duplicate rows.
Q62. What
are the restrictions of Union Transformation?
Ans.
§ All input groups and the output group must have matching ports. The precision, datatype, and scale must be identical across all groups.
§ We can create multiple input groups, but only one default output group.
§ The Union transformation does not remove duplicate rows.
§ We cannot use a Sequence Generator or Update Strategy transformation upstream from a Union transformation.
§ The Union transformation does not generate transactions.
Ans.
§ All input groups and the output group must have matching ports. The precision, datatype, and scale must be identical across all groups.
§ We can create multiple input groups, but only one default output group.
§ The Union transformation does not remove duplicate rows.
§ We cannot use a Sequence Generator or Update Strategy transformation upstream from a Union transformation.
§ The Union transformation does not generate transactions.
General questions
Q63. What
is the difference between Static and Dynamic Lookup Cache?
Ans. We can configure a Lookup transformation to cache the corresponding lookup table. In case of static or read-only lookup cache the Integration Service caches the lookup table at the beginning of the session and does not update the lookup cache while it processes the Lookup transformation.
Ans. We can configure a Lookup transformation to cache the corresponding lookup table. In case of static or read-only lookup cache the Integration Service caches the lookup table at the beginning of the session and does not update the lookup cache while it processes the Lookup transformation.
In case of dynamic lookup cache the Integration Service
dynamically inserts or updates data in the lookup cache and passes the data to
the target. The dynamic cache is synchronized with the target.
Q64. What
is Persistent Lookup Cache?
Ans. Lookups are cached by default in Informatica. Lookup cache can be either non-persistent or persistent. The Integration Service saves or deletes lookup cache files after a successful session run based on whether the Lookup cache is checked as persistent or not.
Ans. Lookups are cached by default in Informatica. Lookup cache can be either non-persistent or persistent. The Integration Service saves or deletes lookup cache files after a successful session run based on whether the Lookup cache is checked as persistent or not.
Q65. What
is the difference between Reusable transformation and Mapplet?
Ans. Any Informatica Transformation created in the in the Transformation Developer or a non-reusable promoted to reusable transformation from the mapping designer which can be used in multiple mappings is known as Reusable Transformation. When we add a reusable transformation to a mapping, we actually add an instance of the transformation. Since the instance of a reusable transformation is a pointer to that transformation, when we change the transformation in the Transformation Developer, its instances reflect these changes.
Ans. Any Informatica Transformation created in the in the Transformation Developer or a non-reusable promoted to reusable transformation from the mapping designer which can be used in multiple mappings is known as Reusable Transformation. When we add a reusable transformation to a mapping, we actually add an instance of the transformation. Since the instance of a reusable transformation is a pointer to that transformation, when we change the transformation in the Transformation Developer, its instances reflect these changes.
A Mapplet is a reusable object created in the Mapplet Designer
which contains a set of
transformations and lets us
reuse the transformation logic in multiple mappings. A Mapplet can contain as
many transformations as we need. Like a reusable transformation when we use a
mapplet in a mapping, we use an instance of the mapplet and any change made to
the mapplet is inherited by all instances of the mapplet.
Q66. What
are the transformations that are not supported in Mapplet?
Ans. Normalizer, Cobol sources, XML sources, XML Source Qualifier transformations, Target definitions, Pre- and post- session Stored Procedures, Other Mapplets.
Ans. Normalizer, Cobol sources, XML sources, XML Source Qualifier transformations, Target definitions, Pre- and post- session Stored Procedures, Other Mapplets.
Q67. What
are the ERROR tables present in Informatica?
Ans.
§ PMERR_DATA- Stores data and metadata about a transformation row error and its corresponding source row.
§ PMERR_MSG- Stores metadata about an error and the error message.
§ PMERR_SESS- Stores metadata about the session.
§ PMERR_TRANS- Stores metadata about the source and transformation ports, such as name and datatype, when a transformation error occurs.
Ans.
§ PMERR_DATA- Stores data and metadata about a transformation row error and its corresponding source row.
§ PMERR_MSG- Stores metadata about an error and the error message.
§ PMERR_SESS- Stores metadata about the session.
§ PMERR_TRANS- Stores metadata about the source and transformation ports, such as name and datatype, when a transformation error occurs.
Q68. What
is the difference between STOP and ABORT?
Ans. When we issue the STOP command on the executing session task, the Integration Service stops reading data from source. It continues processing, writing and committing the data to targets. If the Integration Service cannot finish processing and committing data, we can issue the abort command.
Ans. When we issue the STOP command on the executing session task, the Integration Service stops reading data from source. It continues processing, writing and committing the data to targets. If the Integration Service cannot finish processing and committing data, we can issue the abort command.
In contrast ABORT command has a timeout period of 60 seconds. If
the Integration Service cannot finish processing and committing data within the
timeout period, it kills the DTM process and terminates the session.
Q69. Can
we copy a session to new folder or new repository?
Ans. Yes we can copy session to new folder or repository provided the corresponding Mapping is already in there.
Ans. Yes we can copy session to new folder or repository provided the corresponding Mapping is already in there.
Q70. What
type of join does Lookup support?
Ans. Lookup
is just similar like SQL LEFT OUTER JOIN.
1 comment:
Thank you so much for arrange this queston it really help for me.
Informatica Read Json
Post a Comment